
Ya estamos más que habituados al término Industria 4.0 como sinónimo de la transformación digital del sector industrial. Tal y como os hemos comentado en otros posts de este blog, esta transformación se fundamenta en el uso de tecnologías TIC para mejorar la conectividad entre los diferentes sistemas de una factoría en todos sus niveles, de manera que cualquier elemento (sensor, máquina, MES, ERP, etc.) pueda comunicarse y compartir información con el resto de componentes que integren el ecosistema de producción.
Una de las principales consecuencias relacionadas con la mejora de la conectividad entre sistemas es la disponibilidad de grandes cantidades de datos heterogéneos que puedan estar relacionados con la fabricación o la gestión de la producción y el negocio. Este escenario abre la puerta a una nueva revolución encaminada a su explotación y conversión en información valiosa para la toma de decisiones. Basándose en técnicas estadísticas y modelos complejos de aprendizaje automático o lo que conocemos como Machine Learning, los datos proporcionados pueden emplearse en el desarrollo de aplicaciones para monitorización y control de procesos en tiempo real, la eficiencia energética, la seguridad, la optimización de recursos de producción o el mantenimiento predictivo de equipos de fabricación.
El escenario de globalización y competitividad en el que la industria ha estado inmersa en los últimos años hace que la sostenibilidad actual de las empresas manufactureras se encuentre estrechamente vinculada con el diseño de estrategias centradas en el aumento de la productividad de sus instalaciones, la flexibilidad de sus procesos, la eficiencia de las máquinas y la calidad final del producto fabricado, muy orientadas a lograr la excelencia operacional que garantice su competitividad en el mercado global. Esta tendencia ya la recogían los informes publicados por Mechanical Engineering Industry Association (VDMA) en abril de 2017 y PwC Holanda en junio del mismo año. Por tanto, resulta evidente que la digitalización y el empleo de tecnología aportan mejoras muy importantes relacionadas con la sostenibilidad y la calidad de los procesos y/o productos.
Resulta indiscutible que el uso de procedimientos para analizar la información integrados en los mecanismos de fabricación es un elemento dinamizador clave para la industria manufacturera. La implementación de estos sistemas expertos proporcionará a la industria mejores capacidades para flexibilizar y optimizar de manera continua sus procesos de fabricación, adaptando su comportamiento al estado real de sus recursos en el menor tiempo posible.
¿Qué es el mantenimiento predictivo?
En la actualidad, algunas de las principales aplicaciones de mantenimiento predictivo comerciales se basan en la monitorización del estado de los equipos de fabricación (Condition Monitoring), es decir, la supervisión continua de los principales parámetros operacionales que son indicativos de fallos o errores. Mediante el control de estas variables (por ejemplo, vibraciones de determinados componentes como rotores o motores) y su comparación con umbrales fijos; son capaces de determinar cuándo una máquina empieza a desviarse de su comportamiento habitual. Esta aproximación es muy poco flexible y extremadamente compleja, ya que requiere de una fase previa de estudio y análisis, basada en el conocimiento experto del proceso para determinar qué variables son necesarias monitorizar y el establecimiento de los umbrales indicadores de su comportamiento normal.
El concepto de mantenimiento predictivo es, sin embargo, mucho más amplio y ambicioso. A partir de los datos de máquina recopilados en tiempo real, los algoritmos más avanzados de mantenimiento predictivo basados en técnicas de aprendizaje automático permiten aprender de manera autónoma los patrones de fallo de una máquina y construir automáticamente modelos complejos de varios niveles, capaces de detectar desviaciones sin supervisión experta ni umbrales fijos. Estos algoritmos son capaces de anticipar patrones de fallo que involucran relaciones complejas no lineales entre las variables monitorizadas en una máquina mediante los sensores apropiados, difíciles de detectar mediante las técnicas de Condition Monitoring tradicionales. Además de ser extremadamente flexibles, ya que no es necesaria una fase de análisis previa supervisada por expertos, su integración en frameworks Big Data hace este tipo de aplicaciones mucho más eficientes a nivel de computación y recursos de cálculo cuando el número de equipos o señales a monitorizar es grande.
Las técnicas más avanzadas de mantenimiento predictivo, normalmente relegadas al ámbito académico por su naturaleza innovadora, se basan en el aprendizaje para la caracterización multivariante y automática de patrones de fallo.
Desde el punto de vista de la algoritmia, el mantenimiento predictivo se puede formular siguiendo dos aproximaciones diferentes:
- Un enfoque basado en un problema supervisado de clasificación, en donde se intenta predecir la probabilidad de fallo en un sistema o pieza en los próximos N instantes de tiempo o ciclos de fabricación.
- Un enfoque basado en resolver un problema supervisado de regresión, esto es, estimar cuánto tiempo transcurrirá antes del siguiente fallo (lo que se conoce como cálculo de la vida útil remanente, RUL o Remaining Useful Life).
Un algoritmo de mantenimiento predictivo
A continuación se describirá un algoritmo para la estimación de la vida útil remanente o RUL (basado en técnicas de stacking[1] y ensemble learning[2]) en el que Gradiant está trabajando actualmente. El objetivo de este algoritmo es predecir el número de ciclos de fabricación que restan para que se produzca una parada imprevista de la máquina. Para ello, se entrenará un modelo de regresión complejo de varios niveles que aprenda diferentes patrones de fallo del equipo a partir de los datos de un conjunto de sensores instalados en la máquina que monitorizan en tiempo real su estado, así como información sobre las intervenciones de mantenimiento realizadas en la máquina durante el pasado.
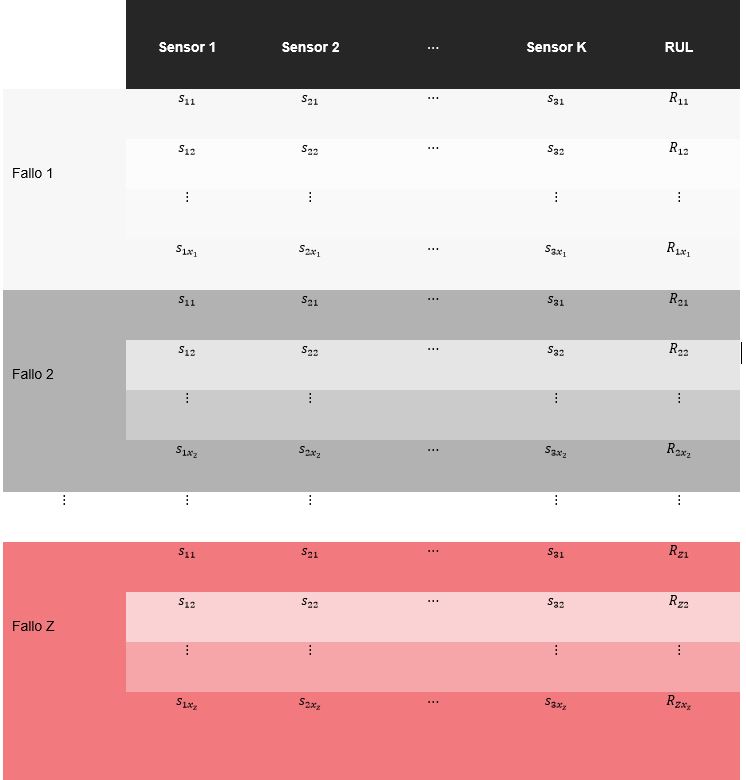
A partir de esta información, se construye un dataset de entrenamiento como el que se muestra en la siguiente tabla, en la que cada valor s_ij representa la salida del sensor i en el instante de tiempo j asociado a cada fallo de máquina, y R_ij como el valor de RUL del patrón de fallo en cada instante de tiempo j asociado a cada una de las averías.
La siguiente imagen (Figura 1) ilustra el algoritmo de mantenimiento predictivo compuesto por tres etapas (o niveles) de regresión diferentes
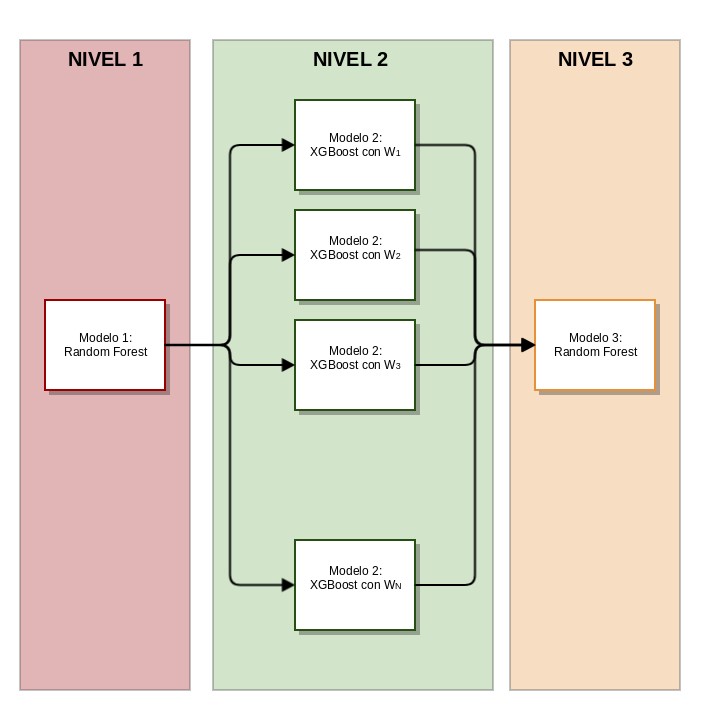
Figura 1: Algoritmo de mantenimiento predictivo
Nivel 1
El primer nivel está compuesto por un único modelo de regresión (Random Forest), encargado de reducir la dimensión del dataset de entrada convirtiendo los datos asociados a cada patrón de fallo en una curva normalizada unidimensional que represente la evolución del estado de la máquina desde su funcionamiento normal hasta el instante de tiempo en el que se produce cada avería (ver Figura 1). La entrada a este modelo estará constituida por los datos de los diferentes sensores instalados en la máquina. La variable objetivo a predecir será un vector compuesto únicamente por unos y ceros, en el que un uno representa aquellos instantes de tiempo en los que la máquina funciona con normalidad (muestras incluidas entre las P primeras, siendo P el 5% de la longitud de cada curva) y un cero representa el conjunto de los instantes de tiempo en los que se produce la avería (muestras incluidas entre las Q finales, siendo Q el 5% de la longitud de cada curva).
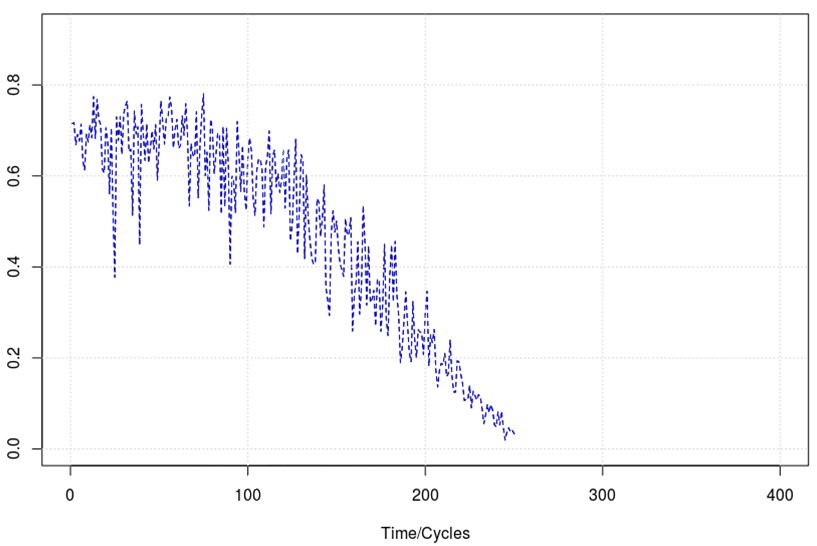
Figura 2: Ejemplo de curva de patrón de fallo
A la salida de este primer modelo, habrá tantas curvas como patrones de fallo en el conjunto de entrenamiento descrito anteriormente.
Nivel 2
La segunda etapa del algoritmo la componen un conjunto N de modelos de regresión (XGBoost) que, a partir de las curvas caracterizadas en la etapa anterior, son entrenados para predecir los ciclos de fabricación restantes hasta que se produzca el siguiente fallo de máquina, esto es, el valor de vida útil remanente o RUL.
Durante el entrenamiento de cada modelo, se define una ventana temporal de tamaño W que se desliza en pasos de una unidad temporal a lo largo de cada curva, desde el inicio (estado normal de funcionamiento de la máquina) hasta el final (instante en el que se produce la avería del equipo). Las variables de entrada a cada modelo serán los W valores de la curva contenidos en la ventana deslizante en cada instante de tiempo, mientras que la variable objetivo a predecir será el valor de RUL en cada caso, esto es, el número de ciclos desde la última muestra contenida en la ventana en cada instante de tiempo hasta el final de la curva correspondiente.
La siguiente imagen ilustra el proceso de entrenamiento de los modelos de regresión de esta etapa
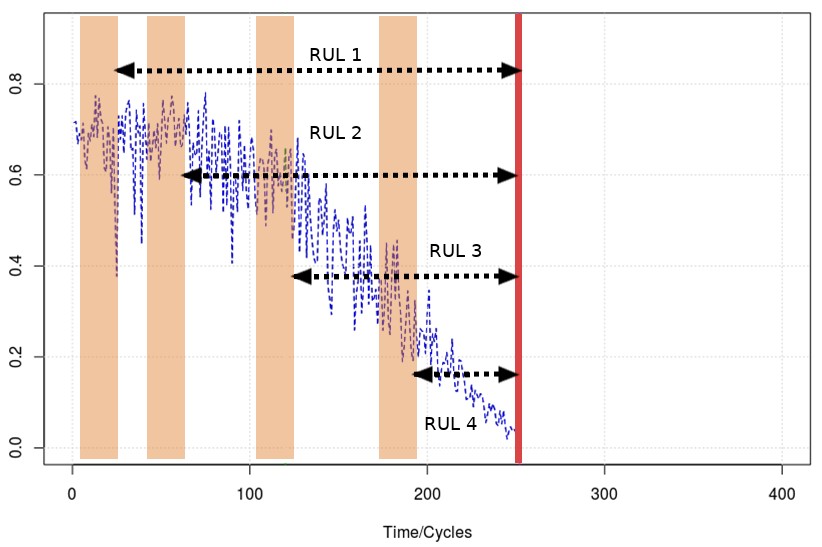
Figura 3: Entrenamiento de los modelos de regresión del nivel 2
Cada modelo de esta etapa será entrenado con una ventana temporal de tamaño W diferente (por ejemplo, W∈ {10,50,80,100,} ).
Durante el entrenamiento de estos modelos se utiliza una función de coste particular que pondera el error de regresión cometido (RMSE o Root-Mean-Square Error) y el número de predicciones que exceden el valor real de RUL, con el objetivo de que los modelos aprendan a penalizar aquellas predicciones que, aunque tengan un error cuadrático pequeño, no hayan sido capaces de anticipar la avería.
Nivel 3
La tercera etapa del algoritmo está formada por un único modelo de regresión (Random Forest) que pondera de manera no necesariamente lineal las predicciones de RUL de cada uno de los modelos anteriores, aprendiendo y seleccionando de entre los N posibles valores vida útil remanente, la predicción más acertada. La entrada a este modelo estará formada, por tanto, por las N predicciones de cada uno de los N modelos que constituyen la etapa anterior. La variable objetivo a predecir será el valor real de RUL.
La siguiente imagen ilustra el resultado de la aplicación del algoritmo descrito tras su entrenamiento con el dataset de A. Saxena and K. Goebel (2008). “Turbofan Engine Degradation Simulation Data Set”, NASA Ames Prognostics Data Repository, que simula los diferentes patrones de degradación de una turbina y un conjunto de sensores que monitorizan su estado a lo largo del tiempo.
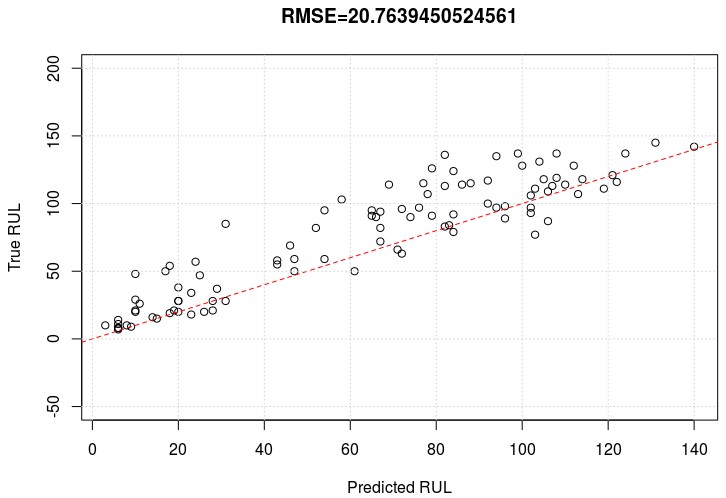
Figura 4: Predicciones vs. Valores reales
En el eje de abscisas se representa el valor de RUL predicho por nuestro algoritmo (esto es, el número de ciclos que restan hasta el próximo fallo de máquina) para el conjunto de datos de evaluación proporcionado. El eje de ordenadas contiene los valores reales de RUL. La línea discontinua de color rojo representa la región óptima en la que las predicciones coinciden exactamente con los valores reales. El error medio cometido por el algoritmo (RMSE) es de, aproximadamente, 21 ciclos. Cabe destacar como la mayoría de las predicciones anticipan correctamente los fallos de máquina imprevistos.
Conclusiones
La conectividad entre sistemas mediante la utilización de tecnologías IT que proclama la cuarta revolución industrial constituye la base principal sobre la que se asienta la aplicación de algoritmos de aprendizaje automático en el sector manufacturero. Esto garantiza la disponibilidad de datos suficientes para la implementación de modelos complejos con los que construir aplicaciones para el control y optimización de cualquier proceso que pueda llevarse a cabo en cualquier factoría.
La explotación de estos datos no sólo permite la flexibilización de la producción, la optimización del uso de los recursos de fabricación o la mejora sustancial de los procesos de control de calidad en tiempo real, sino que también conlleva una notable reducción de costes y el aumento de la productividad, aspectos clave en el actual escenario global y competitivo del sector industrial.
En Gradiant sabemos que la inteligencia artificial es, sin lugar a dudas, uno de los motores fundamentales de la Industria 4.0. Por ello, trabajamos activamente en este campo, investigando y desarrollando diferentes aplicaciones basadas en análisis estadístico y algoritmos de aprendizaje automático que contribuyen a la transformación del tejido industrial en un nuevo modelo de fabricación sostenible e inteligente.
Referencias
[1] WITTEN, Ian H., et al. Data Mining: Practical machine learning tools and techniques. Morgan Kaufmann, 2016.
[2] ZHOU, Zhi-Hua. Ensemble methods: foundations and algorithms. Chapman and Hall/CRC, 2012.
Autor: Bruno Fernández Castro, responsable técnico de Machine Generated Data Analytics (MGDA) en el área de Sistemas Inteligentes de Gradiant.