Nuestro compañero Rafael P. Martínez nos cuenta sobre la importancia de la analítica predictiva en los entornos de Industria 4.0, y sobre cómo el equipo de Data Analytics de Gradiant consiguió una posición privilegiada en la competición sobre este asunto que recientemente organizó la multinacional Bosch.

La analítica predictiva ha comenzado a erigirse como una herramienta fundamental en la digitalización de la Industria 4.0 y, si bien a un ritmo menor del deseable, está siendo explotada por un número creciente de compañías en diferentes sectores productivos.
En un mundo globalizado donde las empresas necesitan reducir costes y a la vez incrementar la calidad de sus productos, resulta complicado no introducir en la ecuación la componente de análisis de los datos que los mismos procesos productivos generan. Tanto es así que, hoy en día, cada vez es más difícil cumplir con los estándares de calidad y de seguridad exigidos sin la intervención de sistemas expertos que ayuden a tomar decisiones de manera ágil y automática. La algoritmia de análisis predictivo se encuentra en el corazón de estos sistemas, permitiendo que las compañías mejoren sustancialmente su eficiencia y competitividad.
El principal reto al que se enfrentan estas soluciones tecnológicas es el de ser capaces de entregar resultados precisos en un tiempo aceptable para que resulten útiles. Sin embargo, en no pocos casos el volumen de datos a analizar pone en riesgo la consecución de ese doble objetivo: precisión y rapidez.
Una aplicación de especial interés para la industria es la detección temprana del funcionamiento anómalo de máquinas o sistemas, imperceptible en muchos casos para el personal humano, pero alcanzable incluso con carácter predictivo con la adecuada monitorización y análisis de los datos que dichos sistemas generan en tiempo real. De esta forma es posible determinar con antelación cuándo una pieza en fabricación va a resultar defectuosa, o qué elementos de la cadena podrían empezar a fallar. Todo ello gracias a la creciente sensorización de las líneas de producción.
La clave: Machine Learning
Para construir un sistema de análisis predictivo se utilizan técnicas de machine learning mediante las cuales es posible entrenar una serie de algoritmos capaces de aprender, generalizar comportamientos y predecir situaciones sobre los datos generados por las fábricas. Este campo de estudio es enormemente amplio, si bien aquí tan solo ofreceremos una referencia superficial a ciertas técnicas que, bien empleadas, pueden ser de gran ayuda en el ámbito de la producción eficiente.
Una de las técnicas que mejores resultados ofrece en la actualidad en problemas de clasificación y regresión es la denominada gradient boosting. A grandes rasgos, consiste en combinar las contribuciones de múltiples modelos sencillos en un modelo complejo para lo cual se optimiza una función de coste de manera iterativa con versiones ponderadas de las muestras de entrenamiento. Esto permite al modelo final aprender progresivamente diferentes aspectos de los datos de entrada. La aplicación de este tipo de técnicas a grandes volúmenes de datos exige una gran cantidad de recursos computacionales, aunque afortunadamente existen implementaciones ultraeficientes, como XGBoost (Extreme Gradient Boosting) o LightGBM (Light Gradient Boosting Machine), ambas basadas en árboles de decisión y paralelización masiva de modelos. XGBoost es una aproximación muy interesante durante una fase de exploración previa por su velocidad de procesado y su capacidad para manejar variables con datos missing. Un modelo XGBoost bien afinado es un buen baseline sobre el que trabajar, aunque todavía quedará mucho por mejorar.
Selección de Características, Stacking, Ensembling
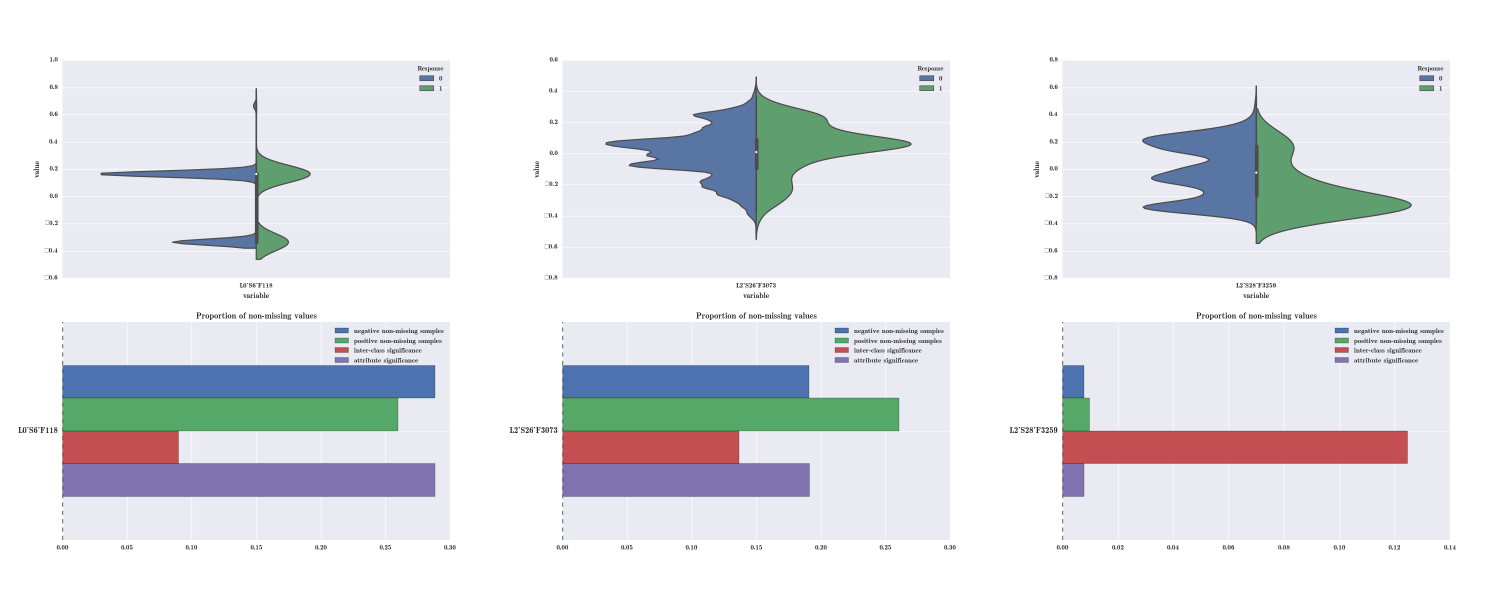
A partir de este punto, el verdadero valor surge del uso de diferentes estrategias que ayudan a maximizar la precisión de los algoritmos. La selección de características y la generación de nuevas características a partir de los datos es lo que hará que nuestro sistema funcione mejor que el resto. Aquí entramos en una fase de «cocina creativa» donde resulta muy útil explorar a fondo los datos con los que se trabaja (obtención de estadísticos de primer y segundo orden), inspección visual de los datos (ver violin/bar plots de la figura inferior). Además, la introducción de conocimiento del dominio permitirá generar nuevas variables que se agregarán a los modelos. Este es el aspecto menos automatizable del proceso (el llamado feature engineering) y donde los analistas consumen la mayor parte de su tiempo. A esto se une el preprocesado de los datos, imprescindible para que los algoritmos puedan comenzar a trabajar.
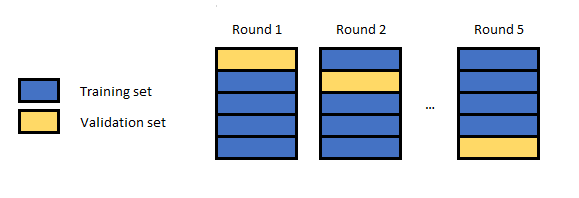
 Una vez definido el conjunto de características, es esencial minimizar posibles problemas de sobreajuste cuando se entrena un modelo, para lo cual es muy recomendable emplear técnicas de validación cruzada sobre los datos de entrenamiento. Esta es una técnica básica que nos ayudará a seleccionar las características más apropiadas para los modelos finales y los parámetros a utilizar.
Una vez definido el conjunto de características, es esencial minimizar posibles problemas de sobreajuste cuando se entrena un modelo, para lo cual es muy recomendable emplear técnicas de validación cruzada sobre los datos de entrenamiento. Esta es una técnica básica que nos ayudará a seleccionar las características más apropiadas para los modelos finales y los parámetros a utilizar.
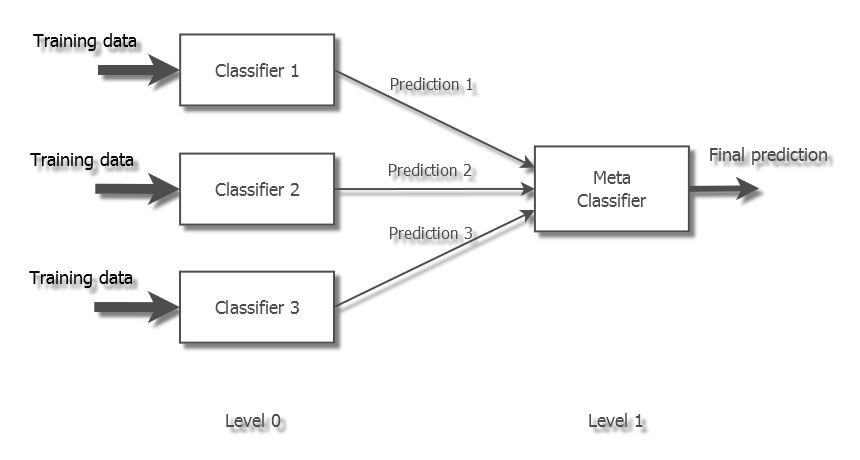
La generación de un modelo bien afinado puede ofrecer resultados competitivos pero los sistemas que ofrecen mejores resultados emplean combinaciones de múltiples modelos. Una vuelta de tuerca habitual consiste en apilar múltiples clasificadores con diferentes ajustes de parámetros (los llamados hiperparámetros) y selección de características, y combinar sus predicciones con el fin de reducir el error de generalización y con ello aumentar la precisión. Este enfoque donde las predicciones de unos clasificadores alimentan las entradas de los clasificadores de la siguiente etapa se conoce como stacked generalization o stacking. Es decir, los clasificadores de una primera etapa forman parte del conjunto de características de la siguiente etapa. El detalle sobre la forma en que se debe realizar el stacking escapa del alcance de este artículo (lo dejamos para otra ocasión), pero conviene tener en cuenta que se trata de un proceso delicado para el que resulta muy sencillo caer en el sobreajuste.
Todas estas estrategias se pueden emplear de manera combinada a lo largo de múltiples etapas para obtener un modelo global con una potencia de predicción que intenta rozar el máximo teórico. El concepto genérico de ensembling propone una estrategia cooperativa donde una gran cantidad de modelos predictivos independientes combinan sus resultados para obtener una mayor precisión y generalización. Aquí pueden entrar en juego técnicas de machine learning muy diversas en busca de la complementariedad: desde regresores y clasificadores de todo tipo (p.ej. XGB, random forest, k-NN, AdaBoost, SVMs, etc) hasta redes neuronales (p.ej. Lasagne, Keras, …). Cuando se aplican técnicas de stacking la diversidad es muy importante. Clasificadores que obtienen malos resultados en una etapa (p.ej. redes neuronales) pueden ayudar a mejorar resultados en etapas posteriores, razón por la que debemos ser cuidadosos a la hora de descartar/seleccionar modelos en la solución final.
Probando fuerzas en Kaggle
Un ejemplo práctico de aplicación de estas ideas ha sido nuestra reciente participación en una competición en Kaggle promovida por la multinacional alemana Bosch. Kaggle provee un escenario fantástico donde equipos de todo el mundo pueden desarrollar sus habilidades y medir sus fuerzas atacando problemas de machine learning. La clave de su éxito radica en que se trabaja con datos reales proporcionados por compañías reales. Además, suele haber interesantes recompensas, lo que supone un factor extra de motivación.
En este caso se trata de una competición en la que Bosch reta a los participantes a predecir fallos en sus líneas de montaje a partir de miles de medidas sobre las piezas fabricadas. Para empezar, nos enfrentamos a un problema verdaderamente Big Data donde cada pieza lleva asociadas alrededor de 4200 variables, siendo necesario analizar los datos de casi 1,2 millones de piezas para anticipar el destino de otras tantas piezas. Para el entrenamiento de los algoritmos hubo que hacer frente a una gran cantidad de valores missing, existiendo además un fuerte desbalanceo entre las clases, ya que solo un 0.
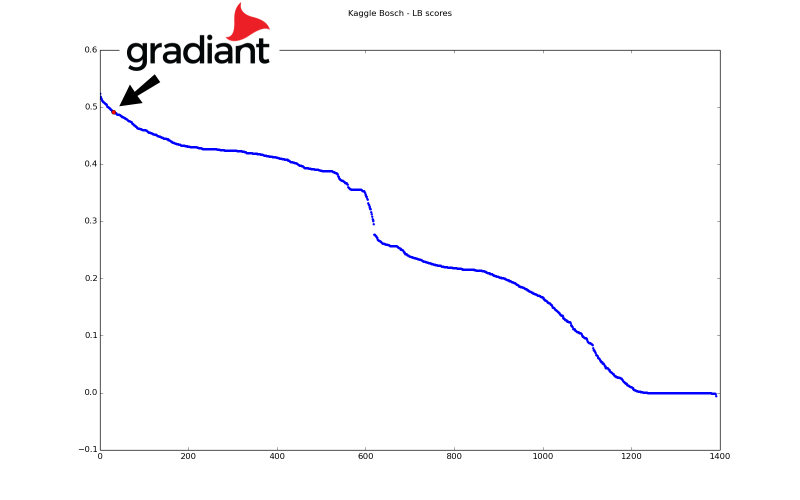
La aplicación inteligente de las técnicas antes mencionadas nos permitió alcanzar una posición muy alta en el ranking: 30 de 1370 equipos participantes, lo que nos situó en el top