
Cybersecurity has become a major issue for organizations. The number of cyberattacks have exponentially increased in the last decade. Cyber criminals rely on an increasing set of powerful tools to exploit organization’s vulnerabilities. The revelation of the CIA’s Vault 7 hacking tools has triggered a global cyber-war.
But, what are the weapons we have to combat the bad guys? Traditional systems such as Antivirus, Intrusion Detection Systems or Firewalls cannot follow all the advances and discoveries of the dark side. Some people point out artificial intelligence as the atomic bomb of the current cyber-war we are living. The future of humankind (or at least their digital future) depends on the winner of this new cyber-arms race.
Gradiant is decided to do their bit to the side of the good guys, and have designed a proof of concept to start applying their knowledge about Machine Learning to the security and intrusion detection domain. We adapted Gradiant’s Stream Analytics Platform to ingest and analyse network related information.
Gradiant’s Stream Analytics Platform can be divided in several layers.
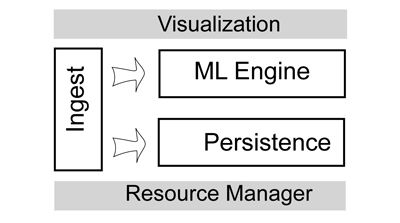
Data Ingestion
Anti-virus, firewalls, Intrusion Detection Systems (IDS), proxies, Security information and event managements (SIEM)… there are multiple types of data sources in the cybersecurity landscape. To provide valuable information to our Stream Analytics Platform we have chosen open-source reference software covering different targets:
- Suricata is a free and open source, mature, fast and robust network threat detection engine. Suricata inspects the network traffic using a powerful and extensive rules and signature language, and has powerful Lua scripting support for complex threat detection.
- Bro supports a wide range of traffic analysis tasks. Bro’s creators emphasize that Bro is not a classic signature-based intrusion detection system (IDS): Bro’s scripting language facilitates different approaches to finding malicious activity, including semantic misuse detection, anomaly detection, and behavioural analysis.
- OSSEC is a scalable, multi-platform, open source Host-based Intrusion Detection System (HIDS). It has a powerful correlation and analysis engine, integrating log analysis, file integrity checking, Windows registry monitoring, centralized policy enforcement, rootkit detection, real-time alerting and active response. It runs on most operating systems, including Linux, OpenBSD, FreeBSD, MacOS, Solaris and Windows.
- Squid offers a rich access control, authorization and logging environment to develop web proxy and content serving applications. Squid can perform caching to save network resources, authentication and authorization, logging, organization internet policy enforcement (content filtering) and network resources usage management.
The messaging system is the main component of the data ingestion layer. All other platform components use the messaging system to consume or produce data. Therefore, previous listed software publish their output as data streams to a dedicated topic of the messaging system.
These dedicated topics serve two purposes: on one hand they act as buffers for bursty producers such as network-related data, and on the other hand they help improve load balancing and scalability by defining partitions and scaling up and down the number of consumers.
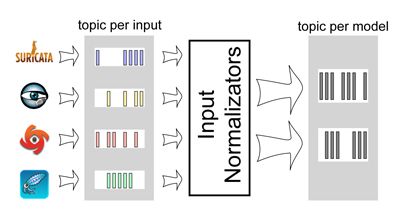
Another important step of data ingestion is normalization. The platform components must receive data with a well-known format. However the platform’s input data is of diverse nature and metrics are not necessarily in coherent scales.
We have defined our own internal data model that all platform components understand. We have been strongly inspired by the Apache Spot Open Data Model proposal, an initiative that is taking the first steps toward a common taxonomy for describing security telemetry data used to detect threats. However this interesting initiative is at an early stage with its proposal still No open for discussion. In order to transform the inputs to the internal data model we have deployed a set of normalizators. The normalizator processes consume events from input topics and produce normalized events to internal topics. These internal topics are the data source of the rest of the platform components.
Machine Learning Engine
Once we had normalized data streams, we attached a Stream Processing Framework to detect possible attacks. This is the core of our playground, and allowed us to experiment with state-of-the-art Machine Learning Algorithms.
For example, we have implemented a ML algorithm that is able to model the role of each host in the network, i.e., if the host is mainly a data producer or a data consumer. Then, the algorithm searches for role changes to detect possible cyberattacks.
Another use case where data analytics and machine learning can play an active role is in the summarization of event logs. Intrusion Detection Systems usually trigger thousands of alerts per day. Due to this amount of events, important alerts can pass unnoticed by the network administrator. Custom configuration of the IDS or output postprocessing are expensive tasks that require expert knowledge. We have applied Pattern-Mining and text clusterization techniques to summarize IDS alerts and highlight alert outliers.
The IDS alerts have also been analysed with process mining techniques. The algorithm generates process models that represent attack strategies. Then the data stream can be analysed in real time to detect an attack process and react even before the attack process completes.
Data Persistence
The data persistence component is composed of a serving layer store and a historic layer store:
- The historic layer store saves a copy of the normalized data streams. The main purpose is to request historic data for complex data modelization, stream replay, root cause analysis and audit. The databases of this layer must handle massive amounts of data and they should be optimized to sustain high writing rates.
- The purpose of the serving layer is to provide optimized responses to queries. These databases aren’t used as canonical stores: at any point, we can wipe them and regenerate them from the output streams or the historic layer store. We consider here full-text search databases for text fields and OLAP databases for numeric fields.
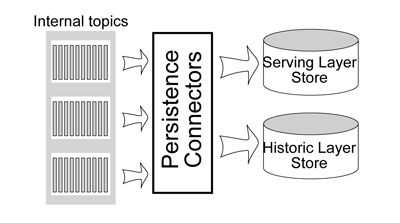
In order to convert data streams to database tables we deploy persistence connector processes that consume events from the internal topics and store them in the serving and the historic layer stores.
Mapping from the internal model to the database’s tables must be done with great care since a bad design choice can highly impact performance. A general rule of thumb in historic layer databases, where massive amounts of data must be indexed and writing speeds are of prime importance, is that table structures must be modelled according to your read queries. Essentially, that means one table serves one query and the databases only support a limited and rigid set of queries.
To support more complex and flexible queries (e.g., OLAP and full-text search) the serving layer store is used. In our design the serving layer automatically provides normalized data from the previous week. Queries with older time ranges are also supported by replaying the stream from the historic layer to a dedicated internal topic.
Showdown
Cards speak for themselves. Here are the technologies and tools we have put in place for setting our Cybersecurity Stream Analytics Playground up and running.
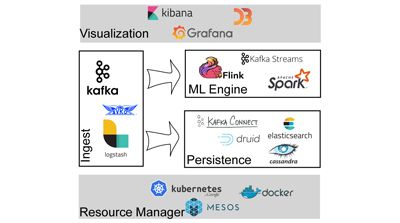
We have now a nice playground to test and validate our research and innovation results in the security and intrusion detection domain. The lesson learned: working with massive scale data streams is not an easy venture, but doing it right and with the correct technologies and tools will help us to get valuable and in time information to solve current and future challenges.
Author: Carlos Giraldo Rodríguez, researcher at Intelligent Networked Systems Department (INetS)