Este contenido se ha publicado originalmente en «Gradiant Talks«, nuestra publicación en la plataforma Medium. Enlace original aquí.
Por Carlos Giraldo

Durante los últimos años ha explotado la tecnología de contenedores en el ámbito TIC, con Docker como abanderado. Inicialmente esta tecnología se ha utilizado, principalmente, para desplegar entornos de desarrollo software y pruebas de forma rápida, aislada y uniforme. Por ejemplo, permite a un desarrollador desplegar un contenedor con una base de datos MySQL mediante un simple comando y en cuestión de segundos disponer del servicio para sus desarrollos. También es posible distribuir una imagen con todas las dependencias necesarias para probar un desarrollo en un entorno aislado y controlado, al igual que puede hacerse con imágenes de máquinas virtuales, pero con ciertas ventajas, como un tamaño más reducido y un menor tiempo de arranque.
La tecnología de contenedores ha evolucionado rápidamente, surgiendo herramientas que permiten el despliegue de contenedores sobre múltiples máquinas físicas o virtuales. Aunque este es un ecosistema muy cambiante, en la actualidad parece que han ganado fuerza Docker Swarm (ahora integrado en Docker Engine a partir de la versión 1.12), Kubernetes (diseñado originalmente por Google) o el más genérico Apache Mesos, así como soluciones completas como pueden ser Rancher o la distribución comercialTectonic.
En Gradiant hemos querido ser partícipes de estos avances, que nos permiten desplegar de forma simple y automatizada entornos de desarrollo o producción con altos requisitos de computación y escalabilidad. A continuación describiremos las etapas necesarias para dockerizar el motor de procesamiento de datos Apache Spark 2.0:
- Una imagen de Docker de Spark optimizada para un despliegue multicontenedor.
- Comunicación entre los contenedores para que puedan formar el cluster Spark.
- Un orquestador para automatizar el despliegue de múltiples contenedores.
Desarrollo
Imagen Docker de Spark 2.0
En el momento de escribir este artículo no existen imágenes oficiales de Spark para Docker. Entre las alternativas aportadas por la comunidad destaca la creada por SequenceIQ con más de cien mil descargas. Sin embargo, la última versión de Spark que proporciona es la 1.6. Además, se trata de una imagen que contiene todas las piezas necesarias para probar Spark en un único contenedor, con lo que tiene un tamaño considerable (2 GB) y no está orientada a su despliegue en un entorno escalable con múltiples nodos.
Una imagen más adecuada para el despliegue en cluster es la creada en el marco del proyecto Big Data Europe, con un tamaño de 512 MB. En cualquier caso, hemos optado por crear nuestra propia imagen, lo que nos permite reducir su tamaño hasta los 233 MB, así como tener control sobre la versión de Spark utilizada (actualmente la 2.0.0) y los componentes disponibles.
El primer paso es seleccionar una imagen de base. De los comienzos de Docker se ha heredado el uso de imágenes de base genéricas de los sistemas operativos más extendidos, como pueden ser Ubuntu, Debian o CentOS. Sin embargo, estas imágenes de base no son adecuadas para crear contenedores ligeros debido a su elevado tamaño (Big Data Europe utiliza Debian 7 como base). Se ha optado por Alpine Linux, una de las distribuciones más populares para servir de base a imágenes Docker. En su página web podemos leer los motivos: Alpine Linux es una distribución Linux independiente, no comercial y de propósito general diseñada para usuarios que aprecian la seguridad, sencillez y eficiencia de recursos. Como Spark necesita también Java, la imagen final elegida es anapsix/alpine-java. Tras descargar Spark 2.0.0, el resto de la magia ocurre en el script de entrada start-spark.sh que hemos desarrollado. Este script admite un argumento para seleccionar el rol del contenedor que se lanzará: master o worker.
Nuestra imagen está disponible en Docker Hub, en el repositorio gradiant/spark.
Comunicación Entre Contenedores
Para la creación del cluster de Spark es necesario que los workers tengan comunicación con el master. Para tal fin se deben cumplir dos condiciones:
- El master debe vincularse con una interfaz, IP o nombre accesible desde losworkers.
- Los workers deben disponer de la IP del master o un nombre que resuelva correctamente a dicha IP, así como conectividad con el mismo.
La dirección de vinculación se le proporciona al master a través de la variable de entorno SPARK_MASTER_HOST. Por defecto la imagen tiene un valor despark-master.
La dirección del master se le proporciona a cada worker a través de la variable de entorno SPARK_MASTER_URL. Por defecto la imagen tiene un valor despark://spark-master:7077.
Para que los contenedores resuelvan el nombre spark-master a la IP correcta nos apoyamos en el servidor DNS para redes definidas por el usuario, una característica introducida a partir de la version 1.10 de Docker Engine. Este servidor DNS proporciona una función de descubrimiento de servicios para cualquier contenedor creado con un nombre o net-alias válido. Las redes definidas por el usuario son redes virtuales que permiten agrupar los contenedores en subredes, según las preferencias del usuario. Antes de esta característica los usuarios solo podían conectar sus contenedores a una única red virtual mediante el bridge docker0, o directamente al host.
Antes del despliegue en el cluster podemos realizar una prueba en local. Creamos la red definida por usuario sparknet, e instanciamos un contenedor Spark master y dos contenedores Spark workers:
docker network create sparknet
docker run -d --net=sparknet -p 8080:8080 --name spark-master gradiant/spark:2.0.0 master
docker run -d --net=sparknet --name spark-worker1 gradiant/spark:2.0.0 worker
docker run -d --net=sparknet --name spark-worker2 gradiant/spark:2.0.0 worker
Para comprobar que la resolución de nombres funciona correctamente y existe conectividad entre los workers y el master podemos ejecutar un comando ping en cada contenedor:
docker exec spark-master ping -c 1 spark-master
docker exec spark-worker1 ping -c 1 spark-master
docker exec spark-worker2 ping -c 1 spark-master
Es posible utilizar nombres personalizados para los contenedores. Solo es necesario sobrescribir las variables de entorno que proporcionan a Spark el nombre del contenedor master, por ejemplo:
docker run -d --net=sparknet --name maestro -e SPARK_MASTER_HOST=maestro gradiant/spark:2.0.0 master
docker run -d --net=sparknet --name esclavo -e SPARK_MASTER_URL=spark://maestro:7077 gradiant/spark:2.0.0 worker
Accediendo a la interfaz de usuario de Spark puede comprobarse el estado demaster y workers:
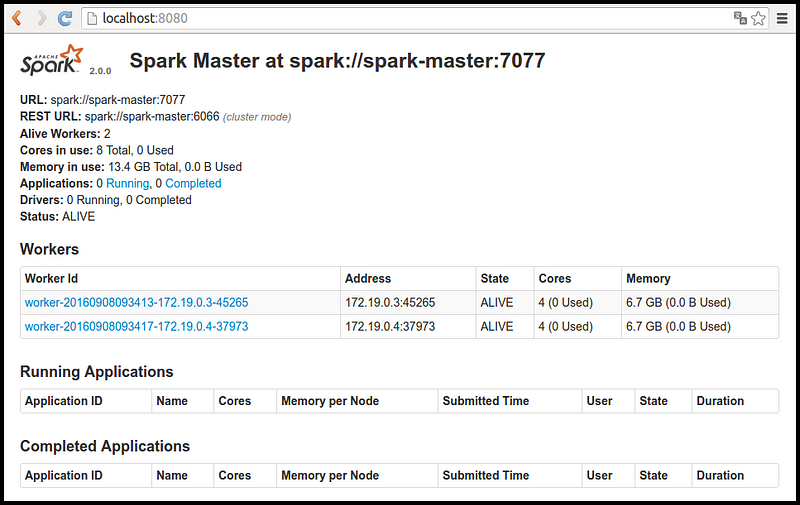
Despliegue Escalable Automatizado
Hasta ahora disponemos de una imagen ligera de Spark 2.0.0 y hemos visto cómo desplegar manualmente múltiples contenedores a partir de esa imagen en la máquina local. Para automatizar y simplificar el proceso de despliegue podemos utilizar un orquestador de contenedores como Docker Compose. Otro problema que nos encontramos es que los workers lanzados en la máquina local están compartiendo los recursos, por lo que la información sobre los núcleos (8) y memoria (13.4 GB) disponibles que proporciona la interfaz de usuario de Spark no es correcta. Necesitamos un orquestador de Infraestructura como Docker Swarm, Kubernetes o Cattle para lanzar losworkers en máquinas diferentes. En nuestro caso hemos probado dos opciones: Docker-Compose con Docker Swarm y Rancher con Cattle.
Compose + Swarm
Docker Compose es una herramienta para la definición y ejecución de aplicaciones Docker multi-contenedor. Compose permite definir los servicios de la aplicación y su configuración en un archivo único. Por otro lado, Docker Swarm permite la utilización de infraestructura distribuida, es decir, múltiples nodos físicos o virtuales, como si fuera una única máquina. El despliegue ha sido probado con Docker Engine v1.11, Docker Swarm v1.2.5 y Docker Compose v.1.8 (su instalación y configuración se sale del alcance de este artículo). La nueva versión 1.12 de Docker Engine integra el modo Swarm e introduce la distribución de aplicaciones mediante Distributed Application Bundle (DAB) a modo experimental. Es posible transformar ficheros docker-compose.yml al nuevo formato .dab, aunque hemos descartado esta opción hasta que sea más estable. Son las desventajas que trae consigo la tecnología de contenedores, que lleva varios años moviéndose muy rápidamente.
En nuestro caso, el contenido del archivo docker-compose.yml es el siguiente:
version: '2' services: spark-master: image: analytics1:35000/gradiant/spark:2.0.0 ports: - "58080:8080" networks: - sparknet command: "master"
spark-worker: image: analytics1:35000/gradiant/spark:2.0.0 networks: - sparknet command: "worker"
networks: sparknet:
Luego, utilizando un solo comando, se pueden crear e iniciar todos los servicios de la aplicación.
docker-compose up -d
Compose permite además escalar los servicios. Si necesitamos más workerspara ejecutar nuestra aplicación Spark podemos lanzarlos con un único comando:
docker-compose scale spark-worker=4
Y comprobar que se han instanciado el número de contenedores indicados y que han sido distribuidos entre los nodos físicos disponibles mediante el siguiente comando:
docker ps --format "table {{.Image}}\t {{.Command}}\t {{.Names}}"
IMAGE COMMAND NAMES gradiant/spark:2.0.0 "start-spark.sh maste" analytics3/spark_spark-master_1 gradiant/spark:2.0.0 "start-spark.sh worke" analytics5/spark_spark-worker_3 gradiant/spark:2.0.0 "start-spark.sh worke" analytics1/spark_spark-worker_1 gradiant/spark:2.0.0 "start-spark.sh worke" analytics4/spark_spark-worker_2 gradiant/spark:2.0.0 "start-spark.sh worke" analytics2/spark_spark-worker_4
Rancher + Cattle
Rancher es una plataforma software de código abierto que permite a las organizaciones ejecutar contenedores en producción. Proporciona orquestación de infraestructura mediante Kubernetes, Swarm, Mesos o Cattle (su sistema propio), orquestación de contenedores con Docker-Compose o Rancher-Compose, un catálogo de aplicaciones, autenticación y control de acceso y una interfaz de usuario amigable.
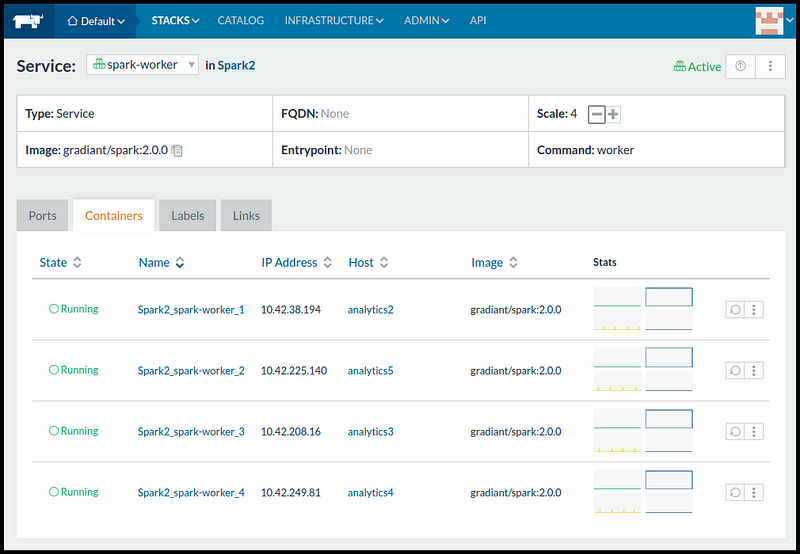
Mediante la interfaz de usuario hemos configurado el Stack Spark2 definiendo los servicios spark-master y spark-worker a partir de la imagengradiant/spark:2.0.0.
En la siguiente captura podemos comprobar cómo Rancher Cattle, al igual que Docker Swarm, ha lanzado cuatro spark-workers distribuidos en cuatro Hosts diferentes.
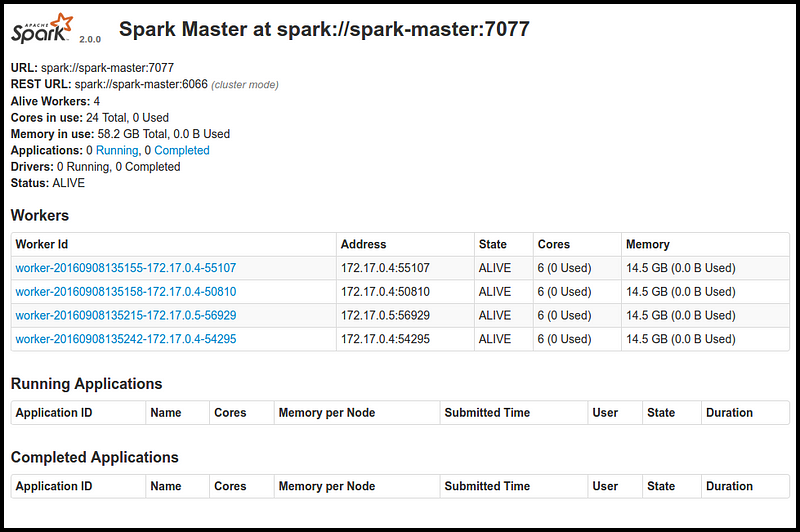
Y cómo spark-master tiene a su disposición los cuatro workers, con un total de 24 núcleos y 58.2 GB de RAM.
Resumen y Conclusiones
Las Herramientas y Frameworks para el Análisis Masivo de Datos requieren del uso eficiente de recursos, generalmente de forma distribuida. Su despliegue y configuración entraña, a menudo, la necesidad de afinar parámetros para su optimización, con una curva de aprendizaje elevada. A esto debemos añadir un ecosistema muy dinámico, donde las herramientas y frameworks están en continua evolución, apareciendo nuevas versiones, nuevas herramientas, o quedando obsoletas otras.
Por estos motivos hemos probado una infraestructura de contenedores distribuidos para nuestro entorno de desarrollo de Análisis Masivo de Datos, lo que nos permite disponer de distintas aplicaciones docker multi-contenedor desplegadas con un simple comando. En este artículo hemos detallado los pasos llevados a cabo para definir de forma simplificada una aplicación multi-contenedor de Spark 2.0, que desplegamos en un cluster con cinco nodos físicos.
Hemos observado cómo los últimos avances de Docker en relación a sus Redes Definidas por Usuario permiten la interconexión de servicios y contenedores a través de su servicio DNS embebido, y cómo las herramientas de orquestación de infraestructura (Docker Swarm, Cattle) y de orquestación de contenedores (Docker Compose, Rancher Compose) permiten el despliegue automatizado de múltiples servicios con un solo click. Aun con la incertidumbre añadida de trabajar en un ecosistema tan innovador y cambiante, hemos comprobado que esta tecnología ha alcanzado un grado de madurez que ha satisfecho nuestras expectativas para el despliegue y configuración de entornos de desarrollo para el análisis masivo de datos.