Hector Cerezo
The Web 2.0 has been a great breakthrough in lifestyle, providing users with new channels of interaction and connectivity. With the new electronic devices, users interact and generate large quantities of information. Most of them carry opinions and knowledge about users. In many web-applications content is tagged as relevant or enjoyable whilst other content is discarded as “spam”.
To improve customer experience, companies track user selections with the aim of offering personalized content to them. This is also known as recommendations. This focused content is based in personal tastes, habits which are gathered from user interactions: navigation flow, e-commerce purchases, product reviews and any other events. Collaborative filtering is a relevant way to achieve reliable recommendations. In this strategy, users get product recommendations based on past preferences of other users alike.
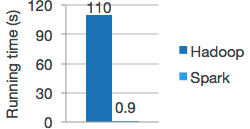
As the interacting possibilities grow, the bigger is the volume of data generated in this process. A new paradigm of computation, “big data”, faces this problem by providing platforms which efficiently process data in the Terabytes range. Hadoop, one of the main contributors to this new way of processing, is not well suited to make recommendations in real time. Hence other technologies complement Hadoop adding new capabilities. For example, Apache Spark offers scalable solutions and is 100 times faster than Hadoop in multiple tasks.
One of the companies who are moving its recommender system to Apache Spark is Spotify (an online streaming music service). They employ recommendations to automatically select next interesting songs to users. In this process, they do collaborative filter over 20 million songs and 20 million users.
In Gradiant, we work in the next generation of recommenders using big data technologies. We employ Spark to analyze customer behavior allowing fast exploration of data and decision making. Also we combine the power of big data platforms with rich visualizations for intuitive data mining and interaction with analysts.