Daniel González Jiménez | Technical Director of Multimodal Information Area
During the last two decades, the growing videogame market as well as players’ enthusiasm for having more and more realistic graphics have motivated the development of new hardware devices, fully devoted to the task of graphic rendering. Those devices, named graphics processors (Graphical Processing Unit, GPU), have evolved from a completely fixed architecture to the fully programmable architecture nowadays available in commercial graphics cards (the first fully programmable graphics processor was the Nvidia GeForce3, which reached the market in 2001).
Besides a fully programmable architecture, current graphics processors specially stand out for their impressive computational capacity, significantly higher than that of general purpose CPUs (e.g. Intel or Amd). However, this computational boosting implies some drawbacks, since the processor control zone is reduced in benefit of computation units, which are more appropriate for graphics rendering, an extremely demanding task in terms of bandwidth-memory and operations-per-second.
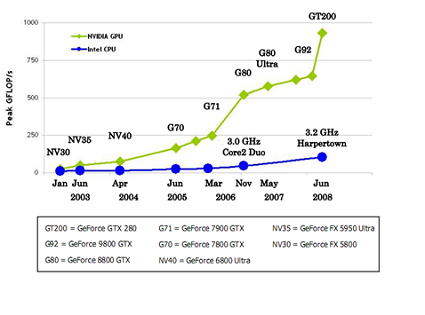
Figure 1. Computational Capacity Comparison (source: www.nvidia.com)
Figure 2 shows the basic differences between a general-purpose processor architecture and a graphics processor architecture. The former is specially designed to control tasks of very different kinds. On the other hand, the GPU architecture is optimized to tackle more uniform and parallelizable computational tasks.
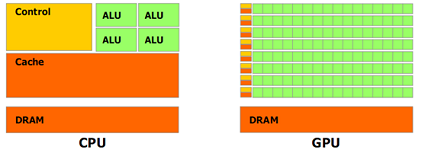
Figure 2. Architecture differences between general purpose processors and graphics processors (source: www.nvidia.com)
Inspired by its efficiency in graphics computation, a new community of developers appeared in 2005, trying to take advantage of the aforementioned potential and use it for more general tasks, rather than exclusively focusing on graphics. This includes, among others, signal and image processing applications, equation solvers, etc.
Up to now, obtained results were impressive in many cases, leading to drastic reductions in execution times, especially when the problem at hand can benefit from the graphics processors’ capacity: fast mathematical operations computation, parallelization, and a huge memory bandwidth (about 100GB/s in the newest devices). This kind of non-graphical application development in graphical processors is called GPGPU (General-purpose computing on graphics processing unit).
The aforementioned factors favored the development of a series of specific programming languages and technologies created to use graphical processors for general computation tasks, being Nvidia the first to publish in February 2007 a full language, named CUDA (Compute Unified Device Architecture). Since this technology allows the simple use of graphics processors (without the need to understand rendering techniques), a fast growing community of developers has emerged, especially within academic research groups. In addition to CUDA, OPENCL is the open source standard for GPU programming languages. Microsoft offers its own solution, DirectCompute, without much success to date. However, it has to be said that not all problems are well suited for a graphics processor architecture, since those that cannot be parallelized or those needing a large number of control flow instructions (e.g. conditional branches) , will take no advantage from this parallel architecture.
Some examples of applications that can clearly benefit from the use of graphics processors are those from the signal and image processing fields, like Fourier-Transforms, autocorrelations (where execution time can be decreased by a 15-20 factor with regard to current processors), Principal Component Analysis (PCA) techniques, medical image analysis, machine learning (e.g. training and testing of Support Vector Machines -SVMs-), LDPC coding/decoding (where execution times can be decreased up to 200 times with large sized codes), matrix factorization, physical system simulation, etc. Overall, graphics processors are, indeed, a powerful and competitive alternative to general purpose processors for computational demanding (parallelizable) algorithms.
Currently, Gradiant is using these technologies to speed up computational demanding problems in the field of pattern recognition, focusing on face recognition, in order to be able to compute a large and diverse number of features, and classify them using complex classification schemes in real time. Moreover, its application to other scenarios of interest in the field of signal processing is already being explored.
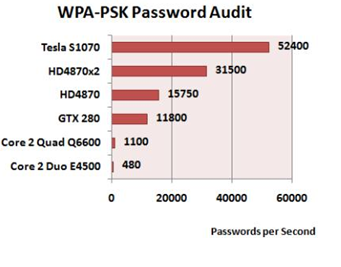
Figure 3. Execution time comparison (source: www.geeks3d.com)