
Al igual que el término Inteligencia Artificial (IA) ha estado denostado durante muchos años, en pleno 2017 el concepto de Big Data comienza algo que genera más rechazo que aceptación debido al desgaste y bombardeo diario. Todo es Big Data y todo se soluciona con Big Data. Pero entonces, ¿qué hacemos los que hacemos Big Data?
Big Data es un concepto que en los últimos años se ha relacionado con grandes cantidades de datos, estructurados o no estructurados, que producen los sistemas o las organizaciones. Su importancia radica no en los datos en sí, sino en lo que podemos hacer con esos datos. En cómo los datos se pueden analizar para tomar mejores decisiones. En muchas ocasiones, gran parte del valor que puede extraerse de los datos proviene de nuestra capacidad para poder procesarlos a tiempo, y por ello es importante conocer muy bien tanto las fuentes de datos como el framework en que los vamos a procesar.
Uno de los objetivos iniciales en todo proyecto Big Data es definir la arquitectura de procesado que mejor se adapta a un determinado problema. Esto incluye una inmensidad de posibilidades y alternativas:
- ¿Cuáles son las fuentes?
- ¿Cómo se almacenan los datos?
- ¿Hay restricciones de cómputo? ¿Y de tiempo?
- ¿Qué algoritmos debemos aplicar?
- ¿Qué precisión debemos alcanzar?
- ¿Cómo de crítico es el proceso?
Es necesario conocer muy bien el dominio para poder contestar a estas preguntas y dar respuestas de calidad. A lo largo de este post propondremos una simplificación de un caso de uso real y comparar dos tecnologías de procesado Big Data.
Caso de uso
El caso de uso propuesto es la aplicación de la arquitectura Kappa para el procesado de trazas Netflow, utilizando distintos motores de procesamiento.
Netflow es un protocolo de red para recolectar información sobre tráfico IP. Nos proporciona información como la fecha de inicio y fin de las conexiones, direcciones IP origen y destino, puertos, protocolos, bytes de los paquetes, etc. Actualmente es un estándar para la monitorización del tráfico de red y está soportado por distintas plataformas hardware y software.
Cada evento contenido en las trazas netflow nos da información extendida de una conexión establecida en la red monitorizada. Estos eventos se ingestan a través de Apache Kafka para ser analizadas por el motor de procesado –en este caso Apache Spark o Apache Flink–, realizando una operación sencilla como es el cálculo de la distancia euclídea entre pares de eventos. Este tipo de cálculos son básicos en los algoritmos de detección de anomalías.
Sin embargo, para poder realizar este procesado es necesario agrupar los eventos, por ejemplo mediante ventanas temporales, ya que en un contexto puramente streaming los datos carecen de un comienzo o un final.
Una vez agrupados los eventos netflow, el cálculo de las distancias entre pares produce una explosión combinatoria. Por ejemplo, en el caso de que se reciban 1000 eventos/s de la misma IP, y que agrupemos cada 5s, cada ventana requerirá un total de 12.497.500 cálculos.
Para aplicar esta estrategia se depende totalmente del motor de procesado. En el caso de Spark la agrupación es directa pues no trabaja en streaming sino con microbatches, así que siempre se definirá la ventana de procesado. Sin embargo, para el caso de Flink este parámetro no es obligatorio al ser un motor puramente streaming, por lo que es necesario definir en el código la ventana de procesado deseada.
El cálculo devolverá como resultado un nuevo stream de datos que se publica en otro topic de Kafka, como se muestra en la figura siguiente. De está manera se consigue una gran flexibilidad en el diseño, pudiendo combinar este procesado con otros en pipelines de datos más complejos.
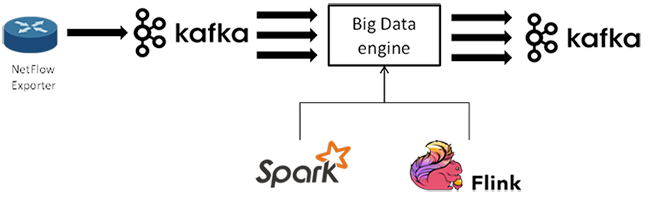
Arquitectura Kappa
La arquitectura Kappa es un patrón de arquitectura software que en vez de usar datos ya almacenados y persistidos utiliza flujos de datos o “streams”. Las fuentes de datos serán, por tanto, inmutables y continuas como pueden ser las entradas generadas en un log. Estas fuentes de información contrastan con las tradicionales bases de datos utilizadas en los sistemas de análisis por lotes o batch.
Estos “streams” son enviados a través de un sistema de procesado y almacenados en sistemas auxiliares para la capa de servicio.
La arquitectura Kappa es una simplificación de la arquitectura Lambda, de la cual se diferencia en los siguientes aspectos:
- Todo es un stream (batch es un caso particular)
- Las fuentes de datos son inmutables (los datos en bruto se persisten)
- Hay un único framework analítico (beneficioso para el mantenimiento)
- Replay functionality, es decir, reprocesar todos los datos analizados hasta el momento (por ejemplo al disponer de un nuevo algoritmo)
En resumen, se elimina la parte batch, favoreciendo un sistema de procesado de datos “in motion”.
Get our hands dirty
Para comprender mejor todos estos conceptos teóricos, nada mejor que profundizar en la implementación. Uno de los elementos que se quieren llevar a la práctica con esta prueba de concepto es poder intercambiar motores de procesado de manera transparente, es decir, que con el mismo código Scala se pueda utilizar Spark o Flink. Por desgracia, ni es tan fácil, ni tan directo, pero sí se puede llegar a una solución común parcial, como se podrá ver en los siguientes apartados.
Eventos Netflow
Cada evento Netflow proporciona información de una conexión específica establecida en la red. Estos eventos son representados en formato JSON y se ingestan en Kafka. Por simplificación, se van a utilizar solo conexiones IPv4.
Ejemplo de evento:
{ «eventid»:995491697672682, «dvc_version»:«3.2», «aproto»:«failed», «src_ip4»:168099844, «dst_ip4»:4294967295, «eventtime»:1490024708, «out_packets»:1, «type»:«flow», «dvc_time»:1490024739, «dst_ip»:«255.255.255.255», «src_ip»:«10.5.0.4», «duration»:0, «in_bytes»:0, «conn_state»:«new», «@version»:«1», «out_bytes»:157, «dvc_type»:«suricata», «in_packets»:0, «nproto»:«UDP», «src_port»:42126, «@timestamp»:«2017-03-20T15:45:08.000Z», «dst_port»:40237, «category»:«informational» }
Parte común
Como se ha mencionado anteriormente, uno de los objetivos de este artículo es utilizar de manera transparente distintos entornos de procesado Big Data, es decir, usar las mismas funciones Scala para Spark, Flink o futuros frameworks. Por desgracia, las peculiaridades de cada framework han hecho que sólo una parte del código Scala implementado pueda ser común a ambos.
El código común incluye los mecanismos para serializar y deserializar los eventos netflow. Nos apoyamos en la librería json4s de Scala, y definimos una case class con los campos de interés:
case class Flow_ip4(eventid: String, dst_ip4: String, dst_port: String, duration: String, in_bytes: String, in_packets: String, out_bytes: String, out_packets: String, src_ip4: String, src_port: String) extends Serializable
Además se define el objeto Flow que implemente esta serialización para poder trabajar cómodamente con distintos motores de Big Data:
class Flow(trace: String) extends Serializable { implicit val formats =DefaultFormats var flow_case : Flow_ip4 = parse(trace).extract[Flow_ip4] def getFlow() : Flow_ip4 = flow_case }
Otro código compartido por ambos frameworks son las funciones para calcular la distancia euclídea, obtener las combinaciones de una serie de objetos y generar el Json de resultados:
object utils { def euclideanDistance(xs: List[Double], ys: List[Double]) = { sqrt((xs zip ys).map { case (x,y)=> pow(y – x, 2) }.sum) } def getCombinations(lists : Iterable[Flow_ip4]) = { lists.toList.combinations(2).map(x=> (x(0),x(1))).toList } def getAllValuesFromString(flow_case : Flow_ip4) = flow_case.productIterator.drop(1) .map(_.asInstanceOf[String].toDouble).toList def calculateDistances(input: Iterable[Flow_ip4]): List[(String, String, Double)] = { val combinations: List[(Flow_ip4, Flow_ip4)] = getCombinations(input) val distances = combinations.map{ case(f1,f2) => (f1.eventid,f2.eventid,euclideanDistance(getAllValuesFromString(f1), getAllValuesFromString(f2)))} distances.sortBy(_._3) } def generateJson(x: (String, String, Double)): String = { val obj = Map(«eventid_1» -> x._1, «eventid_2» -> x._2, «distance» -> x._3, «timestamp» -> System.currentTimeMillis()) val str_obj = scala.util.parsing.json.JSONObject(obj).toString() str_obj } }
Parte específica de cada Framework
En la parte de la aplicación de las transformaciones y acciones es donde las particularidades de cada framework impiden que sea un código genérico.
Como se observa, en Flink se itera por cada evento, filtrando, serializando, agrupando por IP y tiempo y finalmente aplicando el cálculo de las distancias para poder ser enviado a Kafka a través de un productor.
Por otra parte, en Spark, como ya está agrupado por tiempo solo necesitaremos filtrar, serializar y agrupar por IP. Una vez hecho esto se aplicarán las funciones de cálculo de distancia y se podrá enviar a Kafka con las librerías propias.
| Flink |
val flow = stream .filter(!_.contains(«src_ip6»)) .map(trace =>{ new Flow(trace).getFlow() }) .keyBy(_.src_ip4) .timeWindow(Time.seconds(3)) .apply{( key: String, window: TimeWindow, input: Iterable[Flow_ip4], out: Collector[List[(String,String, Double)]]) => { val distances: List[(String, String, Double)] = utils.calculateDistances(input) out.collect(distances) } } .flatMap(x => x) flow.map( x=>{ val str_obj: String = utils.generateJson(x) producer.send(new ProducerRecord[String, String](topic_out, str_obj)) }) |
| Spark |
| val flow = stream.map(_.value()) .filter(!_.contains(«src_ip6»)) .map(record => { implicit val formats = DefaultFormats val flow = new Flow(record).getFlow() (flow.src_ip4,flow) }) .groupByKey() flow.foreachRDD(rdd => { rdd.foreach{ case (key, input ) => { val distances = utils.calculateDistances(input) distances.map(x => { val str_obj: String = utils.generateJson(x) producer.send(new ProducerRecord[String, String](topic_out, str_obj)) }) }} }) |
En el Topic de salida de Kafka se almacenarán los IDs de cada evento, sus timestamps de ingesta, el resultado del cálculo de distancia y el momento temporal en que finalizó dicho cálculo. A continuación un ejemplo de una traza:
{ «eventid_1»:151852746453199<spanstyle=’font-size:9.0pt;font-family:»Courier New»;color:teal’>, «ts_flow1»:1495466510792, «eventid_2»:1039884491535740, «ts_flow2»:1495466511125, «distance»:12322.94295207115, «ts_output»:1495466520212 }
Resultados
Se han ejecutado dos tipos de pruebas distintas, múltiples eventos dentro de una sola ventana, y múltiples eventos en distintas ventanas, donde surge un fenómeno que hace que el algoritmo combinatorio aparentemente tenga naturaleza estocástica y ofrezca resultados distintos. Esto ocurre debido a que se ingestan datos de manera no ordenada, según llegan al sistema, sin tener en cuenta el event time, y se hacen agrupaciones en base a ello, lo que hará que existan combinaciones distintas.
En la siguiente presentación de Apache Beam se explica con mayor detalle: https://goo.gl/h5D1yR
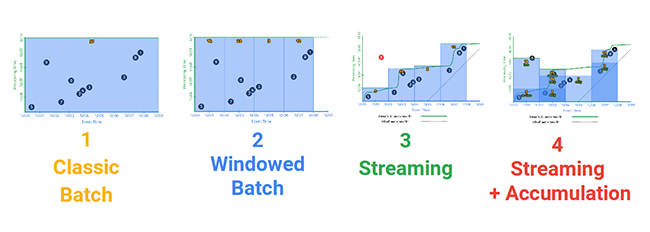
Múltiples eventos en una misma ventana
Se ingestan alrededor de 10.000 eventos en una misma ventana que, aplicando las combinaciones de las mismas IPs, implica un total de casi 2 millones de cálculos. El total de tiempo de cómputo en cada framework (diferencia entre el timestamp de salida más alto y el más bajo) con 8 cores es:
- Tiempo total Spark: 41,50s
- Tiempo total Flink: 40,24s
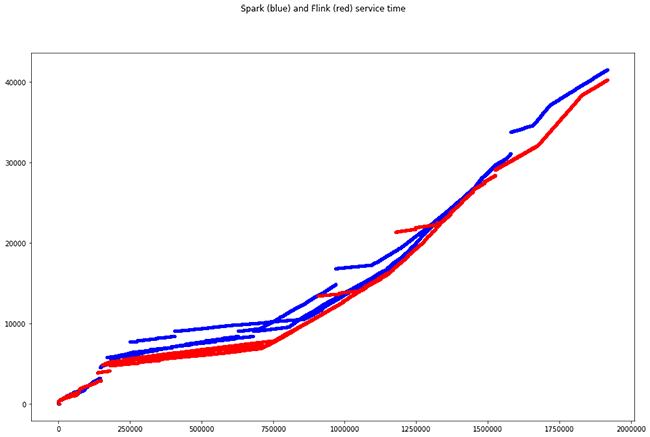
Las múltiples líneas de un mismo color se deben al paralelismo, existiendo cálculos que terminan en el mismo momento temporal
Múltiples eventos en distintas ventanas
Se insertan más de 50.000 eventos, a lo largo de distintas ventanas temporales de 3s. Y es aquí donde se muestran las particularidades de cada motor. Cuando se dibuja la misma gráfica presentada anteriormente (Tiempos de procesado), ocurre lo siguiente:
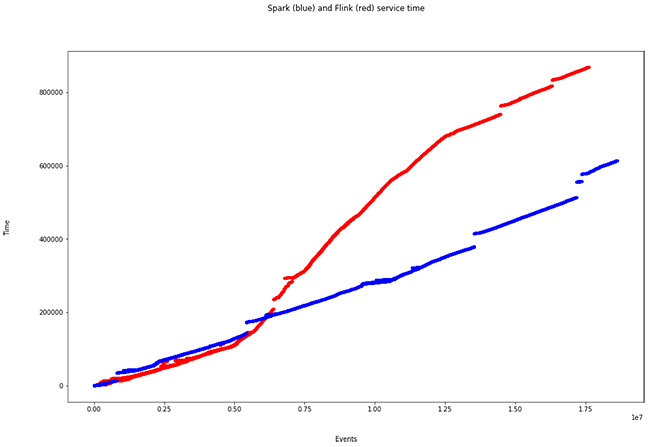
- Tiempo total Spark: 614,1s
- Tiempo total Flink: 869,3s
Se observa un incremento en el tiempo de procesado por parte de Flink. Esto es debido a la forma de ingestar eventos:
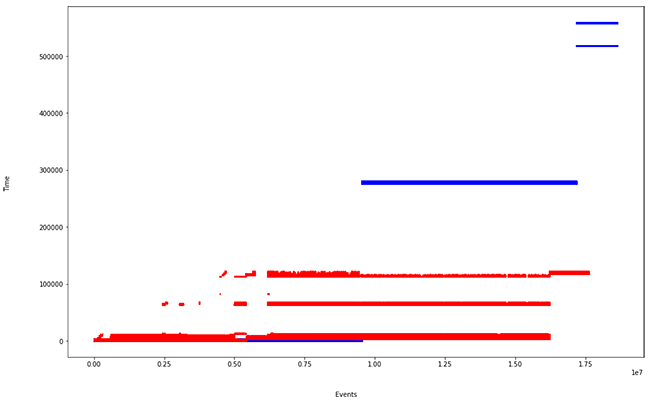
Como se ve en la última figura, Flink, al no tener una estrategia de microbatch, paraleliza el enventanado (a diferencia de Spark, son ventanas deslizantes) y eso provoca un mayor tiempo de cómputo, pero menor tiempo de ingesta. Es una de las particularidades que deberemos tener en cuenta a la hora de definir nuestra arquitectura de procesado Big Data en streaming.
¿Y qué hay del cálculo?
La distancia euclídea de los 10.000 eventos presenta la siguiente distribución:
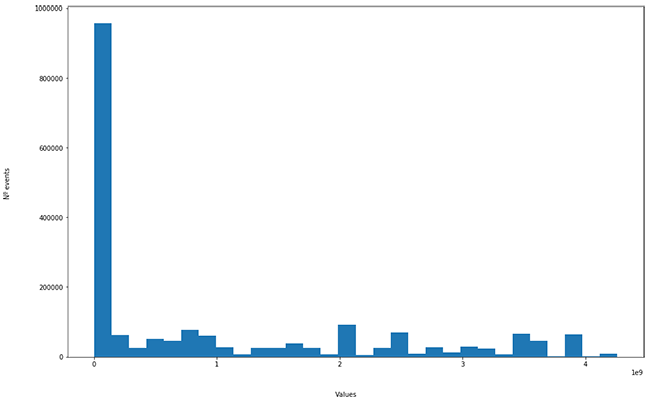
Se asume que lo anómalo es lo que está en la “cola larga” del histograma. ¿Pero realmente tiene sentido? Analicémoslo.
En este caso para el cálculo se están considerando como numéricos ciertos parámetros categóricos (IP, puerto). Se decidió hacerlo así para aumentar la dimensionalidad y acercarnos más a un problema real. Pero esto es lo que obtenemos cuando mostramos todos los valores reales de las distancias:
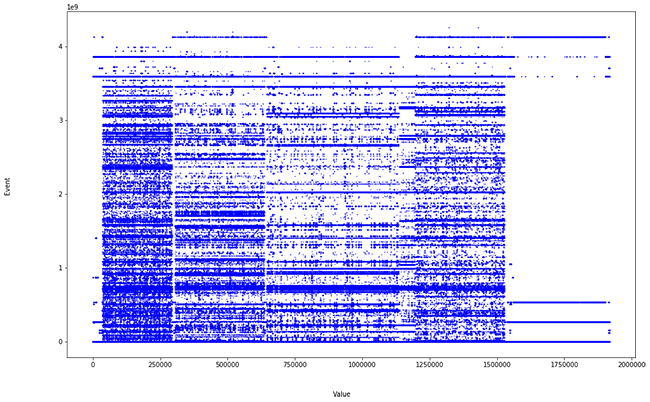
Es decir, ruido, ya que esos valores (IP, puerto, de origen y destino) desvirtúan el cálculo. Sin embargo, cuando eliminamos estos campos y ejecutamos todo de nuevo quedándonos con:
- duration
- in_bytes
- in_packets
- out_bytes
- out_packets
Obtenemos la siguiente distribución:

La cola larga ya no está tan poblada y se observa algún pico al final. Si mostramos los valores del cálculo de las distancias podemos apreciar dónde se encuentran los valores anómalos.
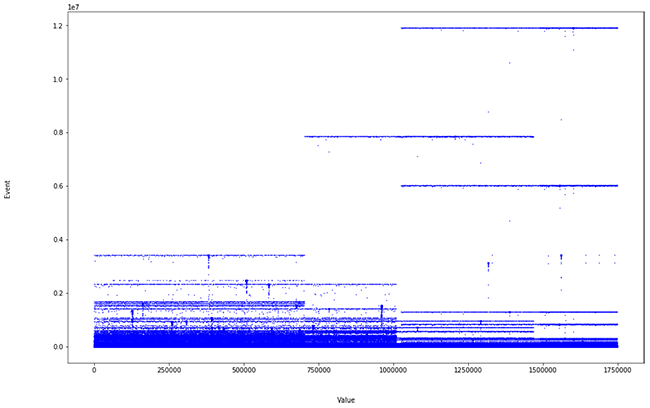
Gracias a este simple refinamiento facilitamos la labor del analista, ofreciéndole una potente herramienta, ahorrándole tiempo e indicándole de manera directa dónde encontrar los problemas de su red.
Conclusiones
Aunque se podrían comentar una infinidad de posibilidades y conclusiones, el conocimiento más destacable obtenido a lo largo de este mini-desarrollo es:
- Framework de procesado. No es trivial pasar de un framework a otro, por lo que es importante desde el primer momento decidir qué framework se va a usar y conocer muy bien sus particularidades. Por ejemplo, si necesitamos procesar un evento instantáneamente y ello es crítico para el negocio, deberemos seleccionar un motor de procesado que cumpla este requisito.
- Big Picture. Para ciertas características un motor destacará sobre otros, pero ¿que se está dispuesto a sacrificar para obtener tal o cual característica?
- Uso de recursos. Gestión de memoria, CPU, disco… Es importante aplicar al sistema tests de estrés, benchmarks, etc para saber cómo se comportará en su conjunto e identificar los posibles puntos débiles y cuellos de botella.
- Características y contexto. Es fundamental tener siempre en cuenta el contexto y saber qué características introducir al sistema. Hemos utilizado parámetros como puertos o IPs en el cálculo de distancias para intentar detectar anomalías en la red. Estas características, a pesar de ser numéricas, no tienen un sentido espacial entre ellas. No obstante, existen maneras de aprovechar este tipo de datos, pero las dejamos para otra ocasión.
Autor: Adrián Portabales Goberna y Rafael P. Martínez Álvarez, investigador – desarrollador senior del área de Sistemas Inteligentes en Red (INetS) de Gradiant